Innodata Inc.: The AI Pick-and-Shovel Pivot
I. Introduction: The 30-Year "Overnight" Success
Picture a fluorescent-lit data center in Noida, India, sometime in late 2023. It is past midnight. A young linguistics graduate is reviewing a string of text generated by a large language model that has, just minutes earlier, been trained on a corpus assembled, in part, by her colleagues two floors down. She marks the response for hallucination, attaches a one-paragraph rationale in markdown, and submits it back into the pipeline. Eight time zones away, a research engineer at a "Magnificent Seven" tech company will pick up the file before their morning espresso. The model will be a little less wrong because of her work.
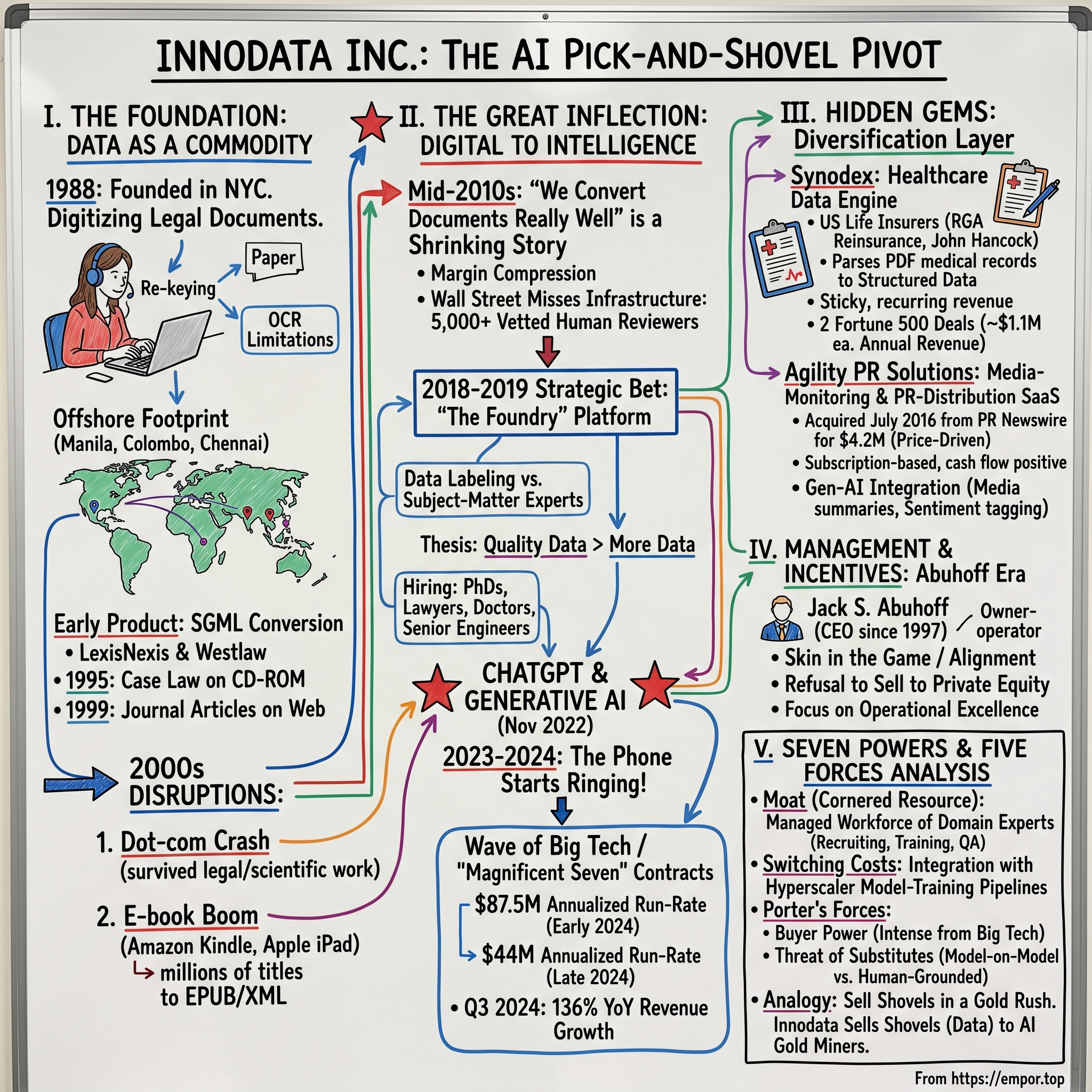
The company that built the pipeline routing her annotation back to that engineer was not Scale AI. It was not Anthropic, or OpenAI, or any of the brand names that dominated AI press in 2023 and 2024. It was Innodata Inc., a New Jersey-headquartered, NASDAQ-listed micro-cap that nobody on Wall Street had bothered to cover for the better part of a decade.1
Innodata was founded in 1988 in New York City to digitize legal and scientific documents — the kind of work that involved teams of operators in offshore production centers re-keying paper into SGML markup so that LexisNexis and Westlaw could sell electronic search to law firms.2 It went public on NASDAQ on August 10, 1993, and proceeded to spend the next three decades cycling through every major content-format transition the industry threw at it: CD-ROM, web, e-book, mobile, cloud.1 Investors, by and large, stopped paying attention somewhere between the dot-com crash and the iPad launch. By the late 2010s the stock was a "zombie" — profitable in some years, loss-making in others, with a market capitalization that hovered in the low nine figures, and the kind of revenue base that institutional money treated as un-investable.
Then generative AI happened. And it turned out that the most boring sentence in technology — "we have 5,000 trained, vetted human reviewers in three time zones who can label your data to a defined quality standard" — became one of the most valuable in the world.
Today the contrast is almost vertiginous. The same company that once shipped pallets of OCR-cleaned text to legal publishers now runs Reinforcement Learning with Human Feedback (RLHF) and Expert-in-the-Loop evaluation programs for the firms building the planet's frontier models.[^3] Revenue more than doubled from FY2023 to FY2024, rising to $170.5 million from $86.8 million.3 Net income turned sharply positive. The stock, which had spent years languishing under $5, was repriced into one of the more spectacular AI-adjacent re-ratings of the cycle.
This is an episode about how that happened. It is a story about a long-tenured CEO who refused to sell when private equity came knocking, about an offshore labor footprint built for one purpose that turned out to be perfect for another, about two small "hidden" businesses tucked inside the holding company that almost nobody talked about, and about the unglamorous economics of "human-in-the-loop" data work in the age of trillion-parameter models. It is, in other words, an Acquired.fm episode about Innodata Inc., ticker INOD, and how thirty years of survival became an overnight success.
Let us start where Innodata started — with paper.
II. The Foundation: Data as a Commodity
In the late 1980s, the cutting edge of "digital content" was not a glowing screen. It was a basement room full of women in headphones, re-keying paragraphs from law reporters into a custom database, with a second operator independently re-keying the same paragraphs so that a comparison program could flag any character that differed between the two. Two-pass keying was the gold standard for accuracy because Optical Character Recognition (OCR) — the technology that today lets your phone read a restaurant menu — was, at the time, barely usable on the kind of badly photocopied case law and medical journals that publishers wanted to digitize.
Innodata was built squarely into that gap. Founded in New York City in 1988 by Todd H. Solomon, the company set out to industrialize the conversion of paper into structured electronic content, with a particular focus on the publishing customers — legal, scientific, scholarly — who needed dense markup and zero tolerance for error.1 The strategic insight was simple but unsexy: the cost of doing this work in midtown Manhattan was untenable, but the cost of doing it in Manila, Colombo, or Chennai, under tight quality controls, was a fraction. By the time the company filed for its IPO and listed on NASDAQ in August 1993, it had already pushed its production base offshore and grown to more than 1,000 employees.1
The early product was SGML conversion — Standard Generalized Markup Language, the elder cousin of HTML and XML. If you bought a CD-ROM of federal case law in 1995, or pulled up a journal article on a publisher's website in 1999, there is a non-trivial chance the underlying markup had been laid in by an Innodata operator on the night shift. LexisNexis and Westlaw were anchor customers in that era, and the work was steady, mechanical, and margin-thin. It was also, crucially, repeatable: the company learned how to spin up a 500-person production team for a new contract, hit a quality SLA, and bill by the page.
The 2000s introduced two waves of disruption — both of which Innodata survived without ever quite breaking out. The first was the dot-com crash, which shrank a lot of the early SGML-conversion budgets at trade publishers but left the core legal/scientific work intact. The second was, paradoxically, the digital book boom. When Amazon's Kindle and Apple's iPad turned every backlist title into a potential e-book, publishers needed somebody to convert millions of titles into EPUB and other XML-based formats at scale. Innodata was already there, with the offshore footprint and the production discipline to do it. The company quietly rode that wave through the early 2010s, growing its publishing services business while OCR and machine translation slowly ate the easier end of its market.
The strategic problem, by the mid-2010s, was that "we convert documents really well" was a shrinking story. Every successive technology made re-keying a little less necessary. Margins on bread-and-butter conversion compressed. Innodata diversified into adjacent niches — content for STM (scientific, technical, medical) publishers, light Business Process Outsourcing (BPO) work, and the two smaller bets we will discuss later (medical-records digitization in insurance, and a PR/media SaaS platform). But the consolidated story was not one a growth investor wanted to own. Revenue bobbed in a range, the stock did very little, and analysts gradually stopped writing.
What Wall Street missed — and what mattered enormously a few years later — was the infrastructure the company had spent thirty years building. Trained, supervised teams of thousands of human reviewers in low-cost geographies. Quality-control software that could enforce inter-rater agreement across a globally distributed workforce. Domain-specialist hiring pipelines in places where domain specialists were both abundant and affordable. Project management muscle that could ingest a customer specification on Monday and have a 200-person team executing against it on Thursday.
In other words: Innodata had, almost by accident, built exactly the operational chassis that would be required to industrialize human feedback for AI. It just did not know that yet, because nobody did.
The pivot, when it came, would not feel like a pivot. It would feel like the same machine being pointed at a different problem.
III. The Great Inflection: From Digitization to Intelligence
Every long-lived company has a moment where the road forks. Innodata's came around 2018–2019, before "generative AI" was a phrase the average tech executive could define. At that point the data services industry had a clear narrative: traditional content conversion was a slow-decline business; the action was in "data labeling" for computer-vision applications — driving lanes for autonomous cars, bounding boxes around tumors in MRIs, that kind of thing. Two competitors, Australia-listed Appen and Canada-based Telus International (which had acquired the labeling firm Lionbridge AI), were building scale in that market with vast crowdsourced workforces.
Innodata's leadership made a quieter bet. Rather than chase the bounding-box commodity, they began building what they would later call a "Foundry" — an integrated platform combining generative-AI-ready labeling, model evaluation, fine-tuning data preparation, and a managed workforce of subject-matter experts.[^3] The thesis was that the next wave of AI would not be about more data. It would be about higher-quality data, generated and graded by humans who actually understood the subject matter — lawyers reading legal prompts, physicians reading medical prompts, software engineers reading code prompts.
It is hard to overstate how heretical this looked at the time. Conventional wisdom in 2019–2020 — and the operating model of the largest data labeling firms — held that scale was the moat. You hired cheaply, you hired massively, you let algorithms do most of the work, and you used humans only for edge cases. Innodata's bet was the opposite: that as models grew more capable, the marginal value of a generic data point would collapse toward zero, while the value of a well-constructed prompt-and-response pair from a domain expert would skyrocket. They started hiring PhDs, lawyers, doctors, and senior software engineers — at Manila and Bangalore wages, but PhDs nonetheless — and folded them into the labeling stack.
Then ChatGPT shipped in November 2022, and the world snapped into focus. Within months, every hyperscaler with a frontier-model ambition realized two uncomfortable things at once. First, that scraping the open web was not going to be enough; the differentiation would come from specialized fine-tuning and from RLHF — reinforcement learning from human feedback, the technique that turned a raw language model into a useful assistant. Second, that they did not have anywhere near enough trained reviewers internally to do the work at the cadence the model release calendar demanded.
For a brief, lucrative window in 2023 and 2024, Innodata's phone started ringing.
The contract announcements came in waves. In early 2024, the company began disclosing a series of multi-year LLM development programs with what it called "Big Tech" customers — the Magnificent Seven of US tech. By mid-2024 Innodata announced a new program and expansion with one such customer valued at approximately $87.5 million in annualized run-rate revenue, and by late 2024 disclosed two additional LLM development programs with another existing Magnificent Seven customer that were expected to deliver roughly $44 million in annualized run-rate revenue.[^3] By the third quarter of 2024 the company's revenue was running at $52.2 million for a single quarter — up 136% year over year — and the customer roster reportedly included five of the seven hyperscalers plus a major AI research lab and a leading social media company.4
For a company that had spent two decades inching its revenue line, this was a different planet. Full-year FY2024 revenue closed at $170.5 million, up 96% over FY2023's $86.8 million.3 First-half FY2025 momentum was even stronger on an organic basis: Q1 FY2025 revenue of $58.3 million, up 120% year over year, and Q2 FY2025 revenue of $58.4 million, up 79% organically.5 Management raised full-year FY2025 guidance to "45% or more" organic growth.6
What investors were paying for, beneath the headline numbers, was the trajectory change. The market began to treat Innodata not as a legacy BPO with a side bet on AI, but as a critical, cornered piece of the LLM training stack — the entity that owned the people, processes, and quality controls that the world's most capitalized tech companies could not stand up internally on the timelines they had committed to.
It is worth pausing to name the analogy that made the trade legible to public-market investors. In a gold rush, sell shovels. In an AI rush, sell labeled data, expert annotation, and human-in-the-loop evaluation. NVIDIA was the obvious shovel — and the most expensive one. Innodata, far down the value chain, was a different and far less crowded shovel: not silicon, but supervision.
That positioning is what re-rated the equity. It is also what set up the bear case we will get to later in this episode.
IV. Hidden Gems: Synodex & Agility
If the AI Data Services story was the spotlight, two quieter businesses were sitting in the wings, doing un-glamorous, recurring-revenue work that gave Innodata's reporting segments more diversification than a casual reader of the headlines might assume.
The first is Synodex, Innodata's healthcare-data engine. The product is deceptively simple to describe. A US life insurer receives an applicant's medical records — typically a multi-hundred-page PDF assembled from various physicians, hospitals, and labs, full of handwritten doctor notes, scanned lab reports, and inconsistently formatted summaries. To underwrite the policy, the insurer needs that document parsed into structured data points: diagnoses, dates, lab values, family history, current medications. Doing this by hand is slow and expensive. Synodex automates the extraction and classification, applying machine-learning models on top of human review, and returns the data in a format underwriters can run rules against.7
The strategic appeal is twofold. First, the work itself is sticky. Once an insurer integrates Synodex into its underwriting pipeline, switching to a competitor means re-validating the entire process — a regulated, auditable nightmare that nobody volunteers for. Second, the addressable market is enormous and embarrassingly manual. There are still major US carriers running medical underwriting on paper-based, partially-keyed workflows, and the secular pressure on insurers to reduce cycle times for life policies pushes more of that work toward platforms like Synodex.
By the late 2010s, Synodex counted among its clients RGA Reinsurance and John Hancock, two of the most established names in US life insurance.8 In November 2022, Innodata announced two additional Synodex platform deals with Fortune 500 diversified financial-services companies, each at roughly $1.1 million of estimated ongoing annual revenue.9 Those are not headline numbers in the context of a $170-million revenue base, but they are the kind of multi-year contracted work that institutional investors will pay a higher multiple for than the lumpy, contract-driven AI Data Services line.
The second hidden business is Agility PR Solutions, the company's media-monitoring and PR-distribution SaaS. The asset was acquired in July 2016, when Innodata's earlier MediaMiser subsidiary purchased the Agility business from PR Newswire for $4.2 million in cash.10 PR Newswire was being acquired itself at the time, and divested non-core assets in the process — so Innodata bought a working SaaS platform, with roughly 1,500 customers and 50 employees split between the US and the UK, at what looks in hindsight like a distress price for that category of asset.10
In the years since, Agility has done what good small SaaS platforms do: grown its subscription base, evolved its product, and quietly thrown off cash. The interesting twist is what happened to it during the generative-AI cycle. PR and communications teams were among the earliest, most enthusiastic adopters of LLM-assisted writing tools — for drafting press releases, summarizing media coverage, sentiment-tagging mentions. Agility integrated generative-AI features for these workflows, which had the dual effect of widening the product's competitive moat against more analog rivals and of giving Innodata a useful internal showcase for the same techniques it was selling to its hyperscaler customers.
Neither Synodex nor Agility is going to make or break Innodata in any given quarter. But together they perform a structural job: they put a layer of stickier, more diversified revenue underneath what is, frankly, a fairly concentrated AI Data Services book. When investors worry — rightly — about Innodata's reliance on one or two giant customers, the existence of two segments that do not depend on those same customers is part of the answer. We will come back to the customer-concentration risk in the bear case, because it is real. But it is meaningfully less acute than it would be if the company were a pure-play AI data shop.
There is also a softer point worth making here. The very existence of Synodex and Agility tells you something about Innodata's culture. This is a company that, across decades, kept testing adjacent applications of its core competency — turning unstructured information into structured information — without ever betting the firm on any single new venture. In a different organization that habit might look like a lack of focus. In this one, it bought a series of cheap options on different futures.
One of those options just turned out to be worth quite a lot.
V. Management & Incentives: The Abuhoff Era
Most public companies do not get to keep the same CEO for nearly thirty years. The list of public-market CEOs who took the chair before the launch of the iMac and are still in the job in 2026 is genuinely short. Jack S. Abuhoff is on it.
Abuhoff joined Innodata's board at the company's founding in 1988, became President and CEO on September 15, 1997, and served as Chairman from May 2001 to June 2020. In November 2025 he re-assumed the Chairman role.11 His background is unconventional for a data-services CEO: a B.A. in English from Columbia College in 1983, a J.D. from Harvard Law School in 1986, and an early career that took him through systems integration and outsourcing rather than enterprise software. Before Innodata he was Chief Operating Officer of Charles River Corporation, a systems integration and outsourcing firm, from 1995 to 1997.11
If you wanted to design a CEO temperamentally suited to running a small, slow-compounding services business through four technology cycles, you would design something close to Abuhoff. He is, by available accounts, neither a charismatic visionary in the Jobs/Musk mold nor a financial engineer in the private-equity mold. He is, instead, an operator's operator — someone who appears to genuinely enjoy the unsexy work of building offshore production discipline, evolving quality-control systems, and managing customer relationships at the line-item level. The phrase that comes up repeatedly in his public interviews is "operational excellence." That is not vocabulary that wins Forbes covers, which may be precisely why Innodata survived to be in the room when generative AI arrived.
The skin-in-the-game story matters here, because Abuhoff has been an owner-operator in addition to a manager. Across the years his beneficial ownership of Innodata stock has typically run in the low-to-mid single-digit percentages of the company, a stake that is meaningful in dollar terms even if it does not approach founder-level control. The proxy disclosures lay out the details year by year.12 Two implications matter for investors. First, the re-rating of INOD over 2023 and 2024 was, on paper, a personally enriching event for the CEO — exactly the kind of outcome that good governance design wants to incentivize. Second, his refusal over the years to engage with the periodic private-equity overtures that come for any sub-scale public services company starts to make more sense. Abuhoff appears to have wanted to run the company, not to sell it.
The pivot to AI Data Services illustrates the temperament well. By the time the contract wave broke in 2023, Innodata had been positioning for it for several years, with R&D and platform investment that depressed near-term margins. A short-tenured CEO with a five-year vesting horizon might have de-risked into cost cuts instead. Abuhoff did not. He had the calendar of someone who had been there before — through the dot-com crash, through the mobile transition, through the long quiet of the 2010s — and could spend organizational energy on a long-dated bet without flinching.
Executive compensation has also been thoughtfully re-pointed at the new model. The most recent proxy filings tie meaningful portions of leadership pay to revenue-growth and operating-income milestones, and over time the emphasis has shifted to align with the AI-driven business rather than the legacy services book.12 That alignment matters less when the company is growing 100% a year and everyone is happy. It matters a great deal in the eventual quarter when growth normalizes and management has to choose between defending margin and chasing the next contract.
The cultural choice that stands out, in our view, is the decision to stay independent. The mid-2010s were brutal for sub-scale public services companies. Private equity, awash in capital, rolled up dozens of competitors in adjacent BPO niches. There is no public record of a serious sale process at Innodata during those years, and Abuhoff's public commentary consistently emphasized independence as a strategic asset. In retrospect, that decision is what made the AI Data Services pivot even possible. A PE-owned Innodata, optimized for cash extraction in 2018, would not have funded the multi-year platform build that made the 2023 contract wins thinkable.
That bridges naturally to the next question, which is: how did Innodata deploy capital across the years, and what does that tell us about the underwriting discipline at the top?
VI. M&A & Capital Deployment: Benchmarking the Bets
For a company of its size and longevity, Innodata's M&A history is striking mostly for what it does not contain. There is no transformational acquisition. There is no ego-driven roll-up. There is, instead, a small handful of carefully sized, opportunistically priced asset purchases, supplemented by significant internal R&D spending and an aversion to leverage that, depending on your investment temperament, looks either disciplined or, until 2023, dull.
The headline transaction is still Agility in 2016. The price tag — $4.2 million in cash for a SaaS platform with around 1,500 customers and 50 employees — was unusually low for a media-intelligence asset, even at the time.10 Comparable SaaS media-monitoring tools in the same period were trading at high single-digit to low double-digit multiples of recurring revenue. PR Newswire was a forced seller because its own parent transaction was reshaping its asset perimeter, and Innodata caught the asset on the way out the door. In Acquired.fm vocabulary: it was a price-driven buy, not a thesis-driven buy. Management saw a SaaS asset trading at distressed economics, with a platform that complemented their MediaMiser product, and they bought it.
The more interesting capital-allocation choice is the one Innodata did not make. By late 2022 and into 2023, the natural play for a public data-services company suddenly facing exploding AI demand would have been to acquire an AI startup. Valuations in the data labeling space had inflated dramatically — Scale AI was raising at a $7 billion valuation in 2021 and would later raise at a $13.8 billion valuation — and any of the dozens of smaller annotation startups in the market would have been willing to be acquired at multiples in the high single digits to low double digits of revenue. Innodata chose, instead, to build its "Foundry" platform internally on top of existing assets and to invest the marginal dollar in hiring domain experts rather than buying engineering teams.
The reasoning, on close reading of the disclosures, was twofold. First, the company believed the binding constraint on hyperscaler-grade AI data services was not software — labeling and evaluation tools were rapidly commoditizing — but trained, supervised human capacity. Buying a 200-engineer startup would not buy you 5,000 reviewers in Manila. Second, paying AI-bubble prices for assets that would then need to be integrated into a labor-driven services organization was, in Abuhoff-flavored vocabulary, not operationally excellent. So they built, hired, and partnered instead.
The capital-allocation pivot inside the company is real, even if it is not loud. Through the mid-2010s, the Innodata balance sheet was conservatively run, with effectively no debt and a posture biased toward preserving cash through the lean years. By 2024, with revenue more than doubling, the company was deploying meaningfully more cash into hiring sprees to fulfill $100M-plus contract clusters — bringing on subject-matter experts, build-out of secured facilities, and management capacity in offshore geographies. Headcount expanded materially as the AI Data Services book scaled.13
What this profile lacks, deliberately, is a flashy acquisition spree to dress up the AI story. There is no analog to the kind of "synthetic data" startup acquisition or "AI-native annotation tool" purchase that might generate a press release and a re-rating. There is also, importantly, no debt-funded buyback program designed to manufacture EPS growth. Capital is mostly going to the operating business — and to the limited extent there is excess, the balance sheet is being preserved as optionality for the next downturn, not extracted.
For a long-term fundamental investor, two questions emerge from this M&A footprint. The first is whether the company will be tempted into more ambitious deals as its stock price provides currency. Public-company history is full of services CEOs who, late in a re-rating cycle, used inflated equity to overpay for poorly fitting acquisitions. The second is whether the internal-build strategy holds when competitors with deeper pockets — and there are several — accelerate their own platform investments. The Agility experience suggests management is patient and price-sensitive. The Foundry experience suggests they are willing to fund multi-year platform bets internally. Neither suggests they will buy something expensive just because the market is open.
So far, capital discipline has been a feature, not a bug. Whether it remains so as the company's profile rises is, in our view, one of the things to watch.
VII. Analysis: Seven Powers & Five Forces
Time to put the company on the analytical chessboard. We will use Hamilton Helmer's 7 Powers and Michael Porter's Five Forces, but we will keep it tight, because frameworks are most useful when they help you see the specific thing — not when they let you tick boxes.
Start with the question that matters most to a long-term holder of any services business: where is the moat?
Cornered Resource: the trained, supervised workforce
Helmer's most demanding power is the cornered resource — a unique input that a company has preferential access to and that produces superior economics. Innodata's version of this is its globally distributed, domain-expert-skewed reviewer base across India, Sri Lanka, the Philippines, and other locations, supported by quality-control systems built up over decades.1 It is tempting to dismiss this as "just labor," but that misses the actual asset. The asset is not headcount; it is managed headcount. It is the recruiting pipelines, the training curricula, the inter-rater reliability scoring systems, the security protocols required to handle hyperscaler IP, and the project management muscle to turn a customer specification into a 500-person production line on short notice. A hyperscaler can hire one PhD reviewer. It cannot, in any reasonable timeframe, hire five thousand.
The relevant question is not whether the resource exists. It clearly does. The question is whether it remains cornered over time. Wage pressure in offshore geographies, competition from Telus International, Appen, and the venture-funded pure-plays, and the eventual entry of hyperscalers' own internal teams all chip at the moat. Innodata's defensible counter is that quality and security clearance, not raw scale, are the binding constraints — and those are slower to commoditize.
Switching Costs: integration with model-training pipelines
Once an Innodata Foundry workflow is embedded in a hyperscaler customer's model-training pipeline — with tooling, file formats, security review processes, and a roster of cleared reviewers — switching to a competitor is non-trivial. It is not as sticky as Synodex switching costs in life insurance, but it is more than zero. The deeper the integration with a customer's RLHF and evaluation loop, the higher the cost of moving.
Scale Economies and Process Power
Innodata also has elements of scale economies (offshore production runs cheaper per unit than smaller competitors can match) and process power (decades of accumulated quality-control playbooks). Neither is exclusive. Both contribute to a structural cost advantage that is hard for new entrants to replicate without years of investment.
Porter's Five Forces
Now flip to the other lens.
Bargaining power of buyers is, frankly, the most uncomfortable force facing Innodata. Five of the Magnificent Seven hyperscalers were reportedly among the customer base by late 2024.4 Those are not customers, in the usual sense. They are gods of the new economy, with effectively limitless choice of vendors, and they regularly extract concessions on price, IP, and contract structure. The mitigation is that Innodata's offering — quality plus security plus domain expertise — sits at the premium end of the data services market, where alternatives are scarce. Even so, the day a major hyperscaler decides to in-source a workflow, a meaningful share of revenue can move.
Threat of substitutes is real and existential, and it is the most interesting long-term question for the entire human-in-the-loop industry. The substitute is not another vendor — it is the model itself. As LLMs become more capable, model-on-model evaluation, synthetic data generation, and self-play training methods can reduce the marginal need for human review. The counter, articulated by Innodata and others, is the "model collapse" thesis: that without ongoing high-quality human-grounded data, model performance degrades, particularly on long-tail and adversarial cases. The truth is probably somewhere in between, and probably moves over time. For now, demand for high-quality human-in-the-loop work has scaled with model size, not against it.
Bargaining power of suppliers — the reviewers themselves — is modest in current conditions but rising. Wages for skilled annotators in India, the Philippines, and Sri Lanka are climbing, and the industry as a whole is consolidating around fewer, larger workforce vendors. Innodata's long offshore tenure helps here; it can recruit faster and retain longer than a newer entrant.
Threat of new entrants is real at the low end (anyone with a Slack channel and a freelancer roster can spin up commodity labeling) and modest at the high end (it is genuinely hard to assemble a domain-expert workforce at scale with security clearance and quality controls).
Industry rivalry is intense in zones where the work has commoditized — see Appen's well-publicized struggles over the past several years[^15] — and far less intense at the expert end, where Innodata, Scale AI, and a handful of others compete on quality and capacity rather than pure price.
Myth versus reality
A useful exercise here. Three pieces of consensus narrative about Innodata are worth checking against the underlying reality:
Myth: Innodata is an "AI company." Reality: Innodata is a services company that sells inputs to AI companies. It does not own a frontier model. It does not have a meaningful proprietary IP layer in the model-building stack. It is, in Acquired vocabulary, a pick-and-shovel provider. That is an attractive position, but it is not the same as being a platform.
Myth: The 2024 contract wins are recurring SaaS revenue. Reality: They are multi-year program commitments from a small number of large customers, with significant flexibility on the customer side as to volume, scope, and renewal. The annualized run-rate disclosures are useful as a directional signal of program scale, not as a SaaS-style ARR figure.[^3]
Myth: The company will be acquired. Reality: Across multiple cycles, with multiple plausible windows for a sale, leadership has consistently chosen independence. There is no evidence in the current disclosures of a strategic review.
These distinctions matter for how you size the position and what multiple you are willing to pay.
VIII. The Playbook: Lessons for Investors & Builders
Step back from the case study, and three lessons stand out for anyone trying to build, invest in, or simply understand the AI economy as it actually is — not as the keynote slides describe it.
Lesson 1: The value of dirty work. Every transformative technology sits on top of a layer of un-glamorous, labor-intensive plumbing. The internet had cable-laying crews. Cloud computing had data-center construction. Generative AI has human review and annotation. The companies that win the plumbing layer rarely win on technology alone; they win because they have already industrialized something that everyone else is going to need but that nobody else wants to do. Innodata's thirty years of paper-to-pixel labor discipline was not a sunk cost. It was the very thing that made the company investable when the AI cycle arrived. The lesson for builders: do not be embarrassed by labor-intensive businesses, particularly in domains where the work cannot be eliminated by automation faster than demand is growing. The lesson for investors: the most interesting "AI exposure" is often not the obvious one.
Lesson 2: The platform trap. It is fashionable to want to be a platform. Platforms have higher multiples, better optics, and bigger TAMs. They are also, in any given category, ferociously contested by deeper-pocketed competitors. Being a service provider to platforms — especially in a wave where platform builders are spending freely on inputs — is, in many cases, the more profitable seat. Innodata's decision in 2023 not to try to be a model company, or even an AI-tooling company, but to be the highest-quality data and review provider to model companies, is a clean expression of this trade-off. The lesson is not "never be a platform." It is "if you cannot be the dominant platform, do not waste capital pretending you can — be the highest-margin supplier to whoever wins."
Lesson 3: Endurance is a strategy. The reason Innodata was in the room when AI happened is that it survived the dot-com crash, the mobile transition, the shift from print to e-book, and a decade of investor indifference. It did so by running profitable in good years, breaking even in bad ones, and avoiding the temptations — leverage, irresponsible M&A, sale to private equity — that ended many of its peers. Endurance in public markets is often dismissed as a lack of ambition. In a long-cycle industry, it is the prerequisite for any kind of ambition at all. The lesson is that founder-CEO longevity, debt aversion, and a culture of operational discipline are not boring features. They are options on futures that have not yet been written.
These lessons are not, importantly, a recipe. Innodata did some of these things deliberately and some of them as the only available alternative. The fact that they composed, in retrospect, into a successful strategy is a useful reminder that strategy at the operating level is often the cumulative result of many small refusals — refusals to overpay, refusals to over-borrow, refusals to abandon the un-glamorous parts of the business — rather than a single bold thesis.
The right way to read Innodata, in our view, is as a case study in capacity built before demand. The capacity was the offshore expert workforce. The demand was generative AI. The lag between the two was about three decades. Patience, in the right kind of business, is not the absence of strategy. It is strategy expressed in geological time.
IX. Epilogue
It is May 2026. The most recent disclosed quarterly data points — Q1 and Q2 of FY2025, with revenues of $58.3 million and $58.4 million respectively, and management guiding to 45%-plus organic growth for the year — describe a business that is still very much in its inflection.56 The customer pipeline, by management's account, remains heavily weighted to Big Tech LLM development programs, with a growing layer of work in adjacent areas: agentic AI evaluation, robotics data, and multimodal model training. New use cases — among them physical AI and robotics — are starting to surface in the company's hiring postings, indicating where the next leg of demand is being sought.
The bull case is, by now, well rehearsed. A small, focused company sits at the chokepoint of a multi-year, multi-trillion-dollar capital expenditure cycle in artificial intelligence, with deep operating infrastructure, low debt, an aligned long-tenured CEO, and two diversifying side businesses. The optionality on adjacent AI applications — robotics, agents, multimodal — is real, and the company's incumbent position with hyperscalers gives it natural at-bats for new programs as those launch.
The bear case is equally important to state, and it is the case to which any serious long-term investor must keep returning. Customer concentration is the headline risk: a meaningful share of the AI Data Services book sits with a small number of hyperscaler customers, and the largest of those customers represented a very large fraction of revenue at recent disclosures.3 Those customers are not loyal in the conventional sense; they will route work to whichever vendor — or to whichever internal team — best fits their needs in any given quarter. Pricing pressure from the buyer side is structural. The substitute risk — synthetic data, model-on-model evaluation, self-play — is the genuine long-term uncertainty for the whole human-in-the-loop industry. And the multiple the equity carried at various points during the re-rating has, fairly or unfairly, priced in a level of execution that leaves little room for an air-pocket quarter.
For long-term fundamental investors, the key performance indicators worth watching, in our view, narrow to just two or three:
-
Concentration and diversification of the top customer cohort. Track the revenue share of the largest Big Tech customer, and the count of distinct Magnificent Seven customers contributing more than a defined threshold. Diversification away from a single customer is the single most important de-risking metric for the next several years.
-
Run-rate revenue conversion. Innodata regularly discloses "annualized run-rate" figures on new programs. The lag between an announced run-rate and the realized revenue in the income statement — and any leakage in that conversion — tells you whether the disclosed pipeline is being faithfully delivered or whether scope is being trimmed under the hood.
-
Margin trajectory. Gross and operating margins reveal whether the company is keeping pricing discipline as it scales. A creeping decline in gross margin, even with strong top-line growth, would signal that the buyer-power problem is starting to show up in the economics.
There is also a set of softer overlays worth tracking. Notable insider sales by the CEO and other long-tenured executives would warrant attention, particularly if they cluster around price highs.12 Any meaningful shift in the customer base — say, the addition of a non-US hyperscaler, or the loss of an existing Magnificent Seven account — would materially change the bull/bear balance. And the periodic re-emergence of the "model collapse" debate in the academic literature is worth watching, because it is the cleanest leading indicator of whether the demand for human-in-the-loop services is structurally durable or cyclically cresting.
Is Innodata, then, the ultimate Cinderella story of the AI infrastructure layer? It is, at minimum, an unusually instructive one. A company founded in 1988 to re-key paper into SGML markup, run by the same CEO since the Clinton administration, with a workforce concentrated in offshore production centers built for an entirely different era — that company is now a critical, named supplier to several of the most capitalized firms in the history of public markets. The narrative arc is almost too clean. The risks ahead are real. The lessons, for both builders and investors, are not.
The episode does not, as Acquired episodes never do, end with a verdict. It ends with a question. In a decade in which most of the public attention — and most of the capital — flowed to the model layer and the chip layer, the durably interesting equity stories may turn out to have been hiding one rung below, in the workforce and tooling that made the models actually useful. Innodata is one expression of that thesis. It will not be the only one. But it may be, in its quiet thirty-eight-year way, one of the early ones to have proven it.
 RSS Feed
RSS Feed Spotify
Spotify Apple Podcasts
Apple Podcasts Amazon Music
Amazon Music Audible
Audible YouTube
YouTube