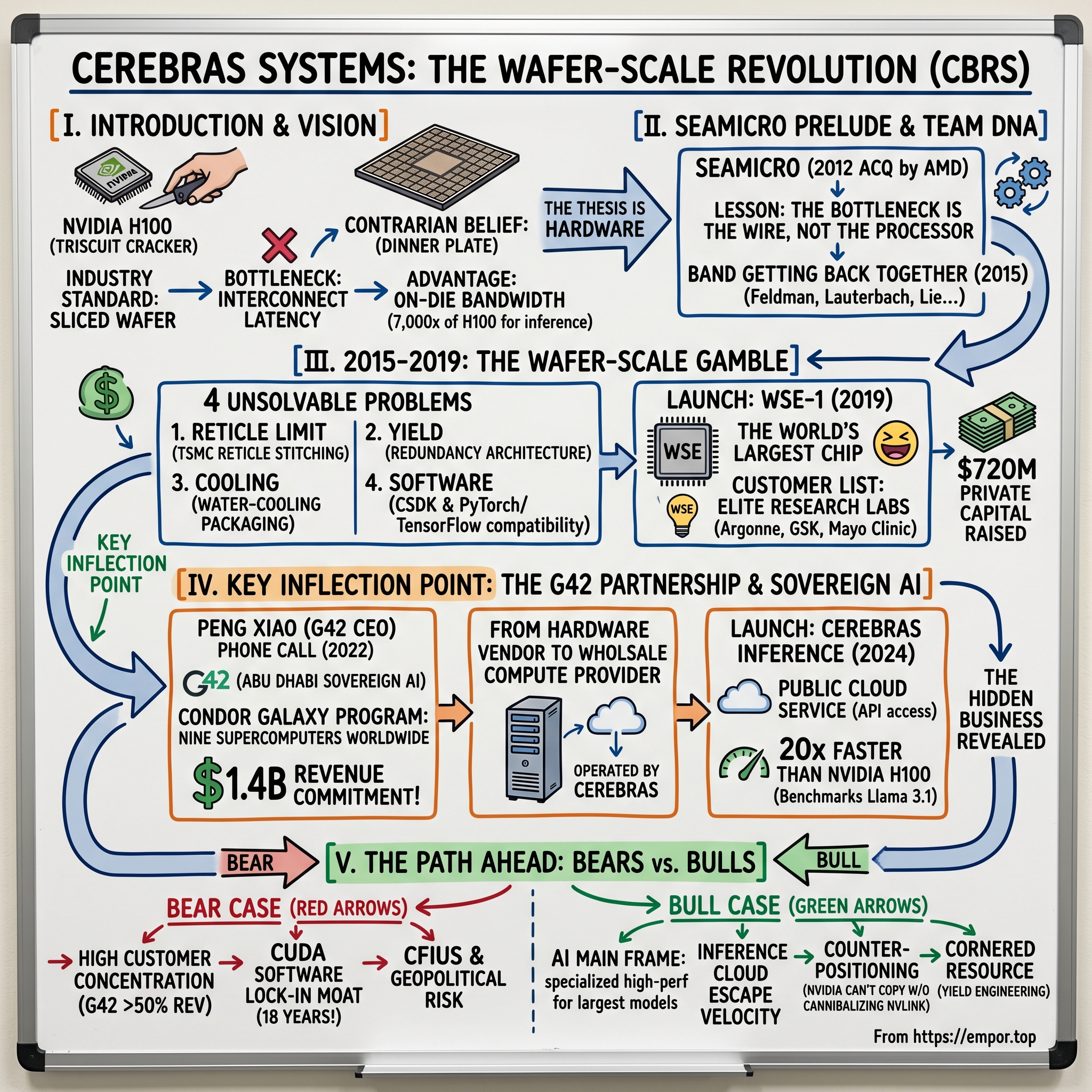
Cerebras Systems: The Wafer-Scale Revolution
I. Introduction: The Dinner Plate in the Data Center
Walk into the cold aisle of any hyperscale data center built in the past five years and you will see, stacked floor-to-ceiling, the same artifact repeated thousands of times: a black, rack-mounted GPU server, humming at 700 watts, holding eight identically-shaped silicon chips, each smaller than a Triscuit cracker. This is the visual language of the AI boom. It is also the visual language of a $3 trillion company called NVIDIA, whose H100 and Blackwell architectures have become the de facto unit of computation for the largest neural networks humanity has ever trained.
Now walk into a Cerebras CS-3 system. The first thing you notice is that there are no chips. There is a chip. Singular. It is roughly the size of a dinner plate, weighs more than a paperback novel, contains four trillion transistors, and consumes the entire surface of a 300-millimeter silicon wafer.[^1] Every other semiconductor company on Earth cuts a wafer into dozens — sometimes hundreds — of small "dies." Cerebras refuses to cut. Their entire business is predicated on a single, contrarian belief: that the act of slicing a wafer into pieces, packaging those pieces, and then stitching them back together with copper, fiber, and PCIe lanes is the single greatest source of latency, power consumption, and software complexity in modern AI compute.
The thesis sounds absurd until you understand the math. Inside an NVIDIA DGX cluster, the most expensive and difficult engineering problem is not the silicon — it is the interconnect. Moving a tensor from one GPU to another, across a server, across a rack, across a row, is orders of magnitude slower than moving it across a single die. The whole industry has organized itself around hiding that latency with NVLink, InfiniBand, NCCL, and a software stack so complex that NVIDIA has, in effect, become a networking company that happens to sell GPUs. Cerebras looked at that picture and said: what if you just never left the chip?
This is the story of how a small group of refugees from a forgotten 2012 acquisition — a company called SeaMicro — bet their second act on the most physically improbable piece of hardware in semiconductor history. It is a story of yield engineering miracles, of a $1.4 billion partnership with an Emirati AI conglomerate few Americans had heard of in 2022, of an IPO held hostage for nearly two years by the U.S. Treasury Department, and of a single chip so large it had to invent its own laws of cooling, packaging, and economics. Along the way, the company has filed an S-1 with the SEC,1 become a publicly-traded NASDAQ stock under ticker CBRS, and positioned itself as the most credible architectural alternative to NVIDIA in a market that has so far refused to tolerate one.
The roadmap for this episode is a chronological arc, but it is really a study of conviction. We will trace the path from the ashes of SeaMicro, through the audacious launch of the Wafer-Scale Engine, through the Condor Galaxy supercomputer constellation now stretching from California to Dallas to the United Arab Emirates, into the cloud business that quietly became the most important number in the S-1 — Cerebras Inference. We will examine the management team, the governance, the bear case (which is real), and the bull case (which is structural). And we will ask the question that every long-term investor in semiconductors eventually has to answer: when the dust settles on the AI build-out of the late 2020s, will the largest models on Earth run on chips the size of crackers, or on chips the size of dinner plates?
So. Let's go back to 2012.
II. The SeaMicro Prelude: The DNA of the Team
The story of Cerebras does not begin in 2015. It begins in a nondescript office park in Sunnyvale, California, in the middle of the global financial crisis, with a server company that almost nobody remembers. The company was called SeaMicro. Its founders were Andrew Feldman, a Stanford MBA who had previously run product at Force10 Networks, and Gary Lauterbach, a legendary chip architect who had designed Sun Microsystems' UltraSPARC processors. They were joined by Sean Lie, Michael James, and JP Fricker — a quartet of engineers whose names would, a decade later, appear together again on Cerebras's founding documents.
SeaMicro's premise was almost the inverse of Cerebras's. Where Cerebras would later argue that you should make the chip as large as physically possible, SeaMicro argued you should make the chip as small as possible and then string thousands of them together with an exotic interconnect fabric. The pitch was for the data center market that, in 2010, was being eaten alive by power costs. Google and Facebook were buying server racks by the megawatt, and most of that power was being wasted on overgrown Xeon cores doing low-utilization web serving. SeaMicro's idea was to take low-power Intel Atom chips — the kind you found in netbooks — and lash 512 of them together into a single 10U server. The interconnect, a 3D torus they called the Freedom Fabric, was the secret sauce.
It was a clever bet, and for a moment, it looked like it might work. SeaMicro shipped product, signed marquee customers like eHarmony and Mozilla, and attracted serious venture money from Khosla Ventures and Draper Fisher Jurvetson. But the macroeconomics of low-power servers in the early 2010s were brutal. Intel woke up to the threat, ARM was still years away from being competitive, and the hyperscalers began building their own custom silicon. In March 2012, AMD — desperate for a story to tell Wall Street as its own CPU business cratered — acquired SeaMicro for $334 million in cash.[^3] Feldman became a corporate vice president at AMD. Lauterbach, Lie, James, and Fricker scattered into senior roles inside the chipmaker.
This is the part of the SeaMicro story that matters for Cerebras. By every conventional metric, the AMD acquisition was a success — the founders got liquid, the employees got paid, the investors got a multiple. But internally, the team came to view the outcome as something closer to a strategic failure. AMD never figured out what to do with the SeaMicro fabric. By 2015, AMD had quietly killed the SeaMicro server line, written off the goodwill, and let most of the original engineering talent walk out the door. Feldman has spoken publicly about the lesson he took from that experience: the bottleneck in modern computing is not the processor; it is the wire. It is the copper, the optical fiber, the PCIe lane, the NVLink — the thing that moves bits from one compute element to another. If you cannot dominate the interconnect, you cannot dominate the workload.
By the spring of 2015, the band was getting back together. Feldman would later describe a series of dinners in Palo Alto where the same five founders met to compare notes on what they had learned inside AMD. The conversation kept circling back to a wild thought: what if, instead of trying to build a better fabric between chips, you eliminated the fabric entirely by building one giant chip? The math seemed insane — a wafer-scale chip would have, at the time, somewhere between 50 and 100 times the silicon area of an NVIDIA GPU. The yield problem alone — the fact that a single random defect anywhere on the wafer would historically kill the entire chip — had defeated every previous wafer-scale attempt going back to Gene Amdahl's Trilogy Systems in the early 1980s. But the math on the upside was also clear: if you could pull it off, you would have a chip with hundreds of times the on-die bandwidth of any GPU, and the AI workloads that were just then beginning to explode would, in theory, scale almost linearly across it.
This is the moment to introduce Andrew Feldman properly, because Cerebras is, in many ways, a one-CEO company. Feldman is not the prototypical Silicon Valley founder. He doesn't wear a hoodie. He is sharp, almost combative in interviews, and famously contemptuous of what he calls the "incrementalism" that has gripped the GPU industry. His self-described philosophy is that startups should do "what is hard, not what is easy" — because what is easy will be done by the incumbent. NVIDIA, in his framing, has too much margin to defend on the H100 and B200 line to ever build a wafer-scale chip. The only company that can do it is one with nothing to lose. In late 2015, with the SeaMicro founders pooling their reputational capital, Cerebras Systems was incorporated. The bet was placed.
III. 2015–2019: The Wafer-Scale Gamble
Cerebras spent its first three years in stealth — an unusually long runway for a hardware startup, but a necessary one. Building a chip is hard. Building a chip that is 56 times the size of the largest chip ever previously manufactured is, in the strict engineering sense, harder than anything anyone in the room had ever attempted. The team had to invent, from first principles, solutions to four separate problems that the rest of the industry had simply declared unsolvable.
The first problem was the reticle limit. Every modern chip is patterned by a piece of equipment called a stepper, which projects an image of the chip's circuitry through a photomask — a "reticle" — onto the silicon wafer. The reticle, by the laws of optics and the physical constraints of the lithography equipment from ASML, can only be so large; in practice, about 858 square millimeters. An NVIDIA H100 is 814 square millimeters and is already considered enormous. Cerebras's WSE-1 was 46,225 square millimeters. To pattern a chip that large, the company had to convince TSMC to do something TSMC had never done in commercial production: stitch multiple reticle exposures together across the wafer with continuous wiring crossing the boundaries.2 This required a custom photomask sequencing process and a new generation of metal layers that could traverse the so-called "scribe lines" — the empty silicon real estate between dies that, on a normal wafer, is where the saw cuts the chip into individual pieces.
The second problem was yield. In a normal semiconductor process, even a state-of-the-art TSMC node produces wafers with dozens of small random defects per wafer — particles of dust, lithography errors, electrical opens or shorts. The chip industry tolerates this because it cuts the wafer into hundreds of dies and discards the defective ones. Cerebras could not discard. A single defect, naïvely, would kill its entire $2 million product. The team's answer was an elaborate redundancy architecture: the wafer was divided into hundreds of thousands of tiny compute cores, with a programmable routing fabric that could simply route signals around any defective core. In effect, the WSE-1 was designed assuming it would ship with thousands of dead cores, and the system would never notice. By the time the WSE-1 was announced at Hot Chips in August 2019, Cerebras claimed it could achieve effectively 100% wafer-scale yield in the field — a claim that, three generations later, no competitor has been able to replicate.[^5]
The third problem was power and cooling. A 46,000-square-millimeter chip, at full tilt, draws roughly 20 kilowatts. You cannot move that much heat off a single piece of silicon with a normal copper heat spreader. Cerebras's engineers built a custom water-cooling system in which a cold plate sits directly on top of the wafer, and a complex set of internal channels delivers chilled water uniformly across the die. The packaging — the assembly that connects the wafer to its power supplies and its host system — is also bespoke, with custom land-grid array connectors and a thermal expansion solution that compensates for the fact that the wafer, the cold plate, and the printed circuit board all expand at different rates as they heat up.
The fourth problem was the one Feldman cared about most: software. A chip with 400,000 cores is useless if a researcher at Argonne National Laboratory cannot write a model that runs on it. Cerebras built, alongside the hardware, a software stack called the Cerebras Software Platform (CSDK), which took PyTorch and TensorFlow models and decomposed them across the wafer's mesh of compute tiles. The pitch to customers was a sleight of hand: yes, the hardware is radically different, but you write the same Python you write for a GPU, and the compiler does the rest. Whether the compiler in fact does all of that — and how the CSDK compares in maturity to NVIDIA's CUDA, which has had 18 years of compounding investment — would become one of the most contested questions in the entire bull/bear debate around the stock.
The capital required to fund this kind of engineering was not trivial. Cerebras raised aggressively across the second half of the decade — Series A in 2016, Series B in 2017, Series C and D in 2018 and 2019, and a Series F that valued the company at $4 billion in 2021.3 The marquee investors were Benchmark Capital (where Bill Gurley personally championed the deal), Altimeter Capital, Coatue Management, Foundation Capital, and Eclipse Ventures. Total private capital raised through 2024 stood at roughly $720 million.3 For context: that is a fraction of what NVIDIA spends on R&D in a single quarter, but it dwarfs what most AI hardware startups have managed. Graphcore, a UK competitor that pursued a different architectural bet, raised similar amounts but burned through its capital while struggling with software adoption. Groq raised less, focused on inference, and has charted its own path. SambaNova raised more — roughly $1.1 billion — but has yet to demonstrate Cerebras's customer concentration in the elite research-lab segment.
By August 2019, Cerebras was ready to come out of stealth. The launch was a kind of theatrical event in the semiconductor world: Feldman walked on stage at Hot Chips in Stanford and held up the WSE-1, a chip so large the audience laughed when they saw it. The headline number — 1.2 trillion transistors — was 56 times the count of the largest GPU then in production.[^5] In the years that followed, the WSE-2 (2021) doubled the transistor count, and the WSE-3 (announced March 2024) reached 4 trillion transistors.[^1] But the more important thing the WSE-1 launch revealed was that Cerebras was not actually selling a chip. It was selling a system — the CS-1, and later the CS-2 and CS-3 — a full-stack box with networking, cooling, and software, priced in the low millions per unit. The business model had quietly evolved from "chip vendor" to "systems integrator," and the customers who placed the first orders — Argonne, Lawrence Livermore, GlaxoSmithKline, the National Center for Supercomputing Applications — were the kind of buyers who buy a system, not a chip.
That was where things stood when, in 2022, a phone call came in from Abu Dhabi.
IV. Key Inflection Point: The G42 Partnership and Sovereign AI
The phone call came from Peng Xiao, the CEO of a company called Group 42, known internationally as G42 — written in Arabic as سلطة 42 in casual rendering but more commonly stylized as مجموعة 42 G42. To understand why this phone call mattered, you have to understand G42, which most American investors had never heard of in 2022 but which had become, by 2024, arguably the most important sovereign technology vehicle outside the United States and China.
G42 is a technology holding company headquartered in Abu Dhabi, chaired by Sheikh Tahnoon bin Zayed Al Nahyan — the UAE's national security adviser and the brother of the country's president. It is, in the technical legal sense, a private company; in the strategic sense, it is the operational arm of the UAE's sovereign AI ambitions. G42 owns or has invested in everything from genomics labs to financial-services platforms to the country's leading large-language-model effort. By 2023, G42 had taken a $1.5 billion strategic investment from Microsoft, a signal that the U.S. government had blessed the Emirati AI buildout as a partner rather than a competitor.
For Cerebras, G42 became something close to an existential customer. In July 2023, the two companies announced what they called the Condor Galaxy program: a planned network of nine AI supercomputers, each powered by Cerebras CS-2 (and later CS-3) systems, distributed across multiple countries and operated by G42 as a sovereign-AI cloud. The first installation, Condor Galaxy 1, went live in Santa Clara, California, with 64 CS-2 systems delivering 4 exaFLOPS of AI compute. Condor Galaxy 2 followed in Stockton, California; Condor Galaxy 3, announced in March 2024, was sited in Dallas, Texas, and built around 64 of the new CS-3 systems with 8 exaFLOPS of compute.[^7] The agreement, by the time it was fully publicly documented in the S-1, represented commitments of roughly $1.4 billion in hardware and services revenue to Cerebras across the multi-year buildout.1
The financial implications were transformative. In the years before G42, Cerebras was a typical capital-intensive hardware company: lumpy revenue, long sales cycles, customers measured in the dozens. After G42, Cerebras had a single counterparty that, on its own, represented the majority of forward bookings. This was simultaneously the best thing that had ever happened to the company and the single largest risk on its balance sheet — a tension we will return to in the bear case.
But the more strategically important consequence of the G42 deal was that it forced Cerebras to confront a question it had been ducking for years: was it a hardware company, or a cloud company? The Condor Galaxy installations were not being sold as boxes to G42; they were being operated by Cerebras on behalf of G42, with G42 in turn reselling the compute to end customers through its own cloud platform. In effect, Cerebras was becoming a wholesale compute provider — selling exaFLOPS as a service rather than CS-3 units. And once the company had built the operational muscle to run sovereign-scale supercomputers for G42, the obvious next move was to start selling that compute on its own behalf, to anyone who wanted it.
That move came in August 2024 with the launch of Cerebras Inference, a public cloud service that allowed any developer with an API key to run large language models — Meta's Llama 3.1 family, the open-weights model from Mistral, and several others — at speeds that were, in independent benchmarks, roughly 20 times faster than NVIDIA H100-based services for the same model.4 The pitch was simple and devastating: while every other AI cloud provider was sitting on a months-long waitlist for H100s, Cerebras could spin up an inference session in seconds, on hardware that was architecturally better suited to the workload than any GPU on the market. The CS-3's enormous on-chip memory bandwidth — roughly 7,000 times the memory bandwidth of an H100 — meant that token-by-token inference, which is memory-bound rather than compute-bound, ran at speeds GPUs simply could not match.
For investors trying to understand Cerebras's trajectory, this was the moment the story changed. Through the WSE-1 and WSE-2 era, Cerebras was a hardware company selling million-dollar boxes to national labs. After Inference, Cerebras was a cloud-and-hardware hybrid with a high-margin recurring revenue stream sitting on top of a capex-heavy systems business. The S-1 filings broke this out explicitly, and the segment growth rates told the story: hardware revenue grew, but Inference and Cloud grew faster. The hidden business, as the outline calls it, was no longer hidden.
That recasting — from "the wafer-scale chip company" to "the AI cloud that happens to own the most exotic silicon on Earth" — became the central narrative of the IPO.
V. Management, Governance, and Shareholding
The most important sentence in the Cerebras S-1, for anyone trying to understand how the company is run, is buried about 200 pages in: Andrew Feldman, as of the IPO filing, controlled a high-single-digit to low-double-digit percentage of the company's voting shares on a fully diluted basis, with his stake further fortified by a dual-class share structure that gives founder shares enhanced voting rights.1 In plain English: Feldman is not going anywhere, the board cannot push him out without his consent, and the long-term strategic direction of the company is, for all practical purposes, his personal decision.
This is unusual for a deep-tech hardware company. Most chip startups, by the time they reach IPO, have been through enough capital raises and enough product delays that the founders have been diluted into single-digit minority positions, with the board effectively controlled by the late-stage growth investors. Cerebras's cap table reflects a different reality. Because the company raised relatively efficiently — $720 million across nine years for a hardware company is genuinely tight discipline — and because the late-stage rounds came at high valuations driven by genuine commercial traction rather than a cash-burn rescue, the founder team's economic stake was preserved.3 Sean Lie, the chief hardware architect, and Gary Lauterbach, the chief technical adviser, each retain meaningful equity. Michael James and JP Fricker, the other two original SeaMicro alumni, remain in senior technical roles.
The board, as constituted at IPO, reflects this founder-centric posture. Bill Gurley of Benchmark holds a seat (and has, by all accounts, been Feldman's most consistent external advocate since the 2017 Series B). Glenn Hutchins of North Island Ventures and Pure Capital sits on the board, bringing financial-services and infrastructure expertise. The remaining seats are filled by independent directors with backgrounds in semiconductor operations and large-enterprise sales. Notably, no Emirati director sits on the board despite G42's status as the largest customer and a major equity holder — a deliberate governance choice that Cerebras's lawyers worked hard to engineer in order to avoid triggering further CFIUS scrutiny.
This brings us to the CFIUS problem, which deserves its own paragraph because it nearly killed the IPO. After Cerebras filed its S-1 with the SEC on September 30, 2024,1 the offering immediately ran into questions from the Committee on Foreign Investment in the United States (CFIUS) about whether G42's equity position in Cerebras — which had been built up through multiple tranches of strategic investment alongside the Condor Galaxy purchase commitments — constituted a foreign-government-linked holding that required formal review. The IPO sat in regulatory limbo for the better part of 2025. Cerebras's eventual path through CFIUS required a structural concession: G42 agreed to convert a portion of its equity into non-voting shares, and the U.S. government received certain ongoing reporting rights over Cerebras's technology transfers. With that resolved, the IPO eventually priced, and CBRS began trading on NASDAQ.
For investors, the governance picture has two implications. First, this is a founder-led company in the strongest sense of the term — decisions about R&D allocation, customer concentration, and strategic positioning will continue to reflect Feldman's personal judgment rather than the average view of an institutional board. Second, the dual-class structure means that traditional governance activism — pressure from large index holders to spin off the cloud business, or to return capital, or to slow R&D spend — has limited leverage. You are buying a founder's company. That is a feature for some, a bug for others.
The compensation structure echoes the founder-aligned philosophy. According to the S-1 disclosures, executive compensation at Cerebras is unusually heavy on equity and unusually light on cash, with the named executive officers' incentive plans tied to a combination of R&D milestones (the successful tape-out of next-generation WSE designs, the achievement of specific Cerebras Inference latency targets) and recurring-revenue growth metrics rather than simple hardware-shipment counts.1 This matters because it tells you what management is being paid to do. They are not being paid to ship more CS-3 boxes per quarter; they are being paid to grow the cloud business and to extend the architectural lead on the next chip. Whether the public market, which tends to reward predictable quarterly box-shipments, will tolerate that incentive design over time is one of the more interesting open questions of the post-IPO period.
The other thing worth noting about Cerebras's leadership: it is small. The senior team that built and shipped the WSE-3 numbers in the low hundreds of engineers, against an NVIDIA design team measured in the tens of thousands. Feldman has been explicit, in public interviews, that he sees this as a strategic asset rather than a constraint — the wafer-scale architecture, in his view, requires fewer people to design because it eliminates the entire interconnect engineering layer that consumes most of a GPU company's engineering headcount. Whether that thesis holds up as the WSE-4 and WSE-5 cycles approach is another open question.
VI. Segment Data and the Hidden Business
The Cerebras S-1, when stripped of its safe-harbor language and read as a business document, tells a story of three businesses sitting awkwardly inside a single corporate shell. Understanding how they relate to each other is the central analytical exercise for any long-term investor in the stock.
The first business is hardware systems. This is the original Cerebras: selling CS-3 boxes (and the previous-generation CS-2) to elite buyers who can write a multi-million-dollar check for a single piece of compute infrastructure. The customer list is small but prestigious — Argonne National Laboratory, Lawrence Livermore, Pittsburgh Supercomputing Center, the Mayo Clinic, GlaxoSmithKline, AstraZeneca, the U.S. Department of Energy, Sandia National Laboratories. Each of these accounts is a multi-year relationship in which Cerebras sells an initial system, then layers on services, software upgrades, and follow-on hardware as the model sizes the customer is training keep growing. The unit economics are reasonable but the growth curve is constrained by the simple fact that the number of customers on Earth willing to buy a $2 million single-box AI accelerator is finite. This business will probably grow at a respectable single-digit-to-low-teens percentage per year, but it will not, on its own, justify the multiple the market is paying for CBRS.
The second business is AI Cloud and Inference — what Cerebras calls, internally, the "real growth engine." This is the public cloud service launched in August 20244 together with the wholesale-compute arrangement Cerebras operates for G42. The unit economics here are radically different from the hardware business. Instead of selling a CS-3 once for $2 million, Cerebras retains ownership of the system, deploys it in its own (or G42's) data center, and rents the compute by the hour, by the token, or by the API call. The gross margin on cloud inference, once the data center is built and amortized, can be substantially higher than the gross margin on a one-time hardware sale — though the capital required to build that data center is also substantially higher, which is why Cerebras's free cash flow profile in the S-1 looks more like a hyperscaler than a chip company. The Cerebras Inference public API, in particular, has gained meaningful developer mindshare in the months since launch, driven by the simple and verifiable fact that for a developer wanting to run a Llama 3.1 70B model with sub-100-millisecond latency, the Cerebras endpoint is roughly an order of magnitude faster than the comparable NVIDIA-based offering on AWS Bedrock or Together AI.4
The third business is sovereign AI partnerships. The Condor Galaxy program with G42 is the flagship,[^7] but the S-1 hints at additional sovereign discussions. The pitch to nation-state customers is straightforward: if you do not want your national AI strategy to depend on the export licensing decisions of the U.S. government as they relate to NVIDIA's GPUs, you can buy a non-export-controlled architectural alternative from Cerebras. The wafer-scale chip, by virtue of being a system-level product rather than a GPU, has historically sat in a different export-control category than a discrete H100 — although the regulatory landscape here is fluid and could change quickly. This third segment is the most speculative and the highest-variance: a single new sovereign deal could double the company's forward bookings; a deal that falls through could materially reset the growth story.
One question investors keep asking is why Cerebras has not pursued M&A more aggressively. NVIDIA built its modern moat largely through acquisitions — Mellanox in 2019 to lock down the InfiniBand interconnect, the attempted (and ultimately blocked) Arm acquisition in 2020, the Run:ai purchase in 2024 to extend into orchestration software. Cerebras, by contrast, has done essentially no M&A in its nine-year history. The official answer, when Feldman has been asked, is that the architectural integration challenge of bolting an acquired software stack onto the wafer-scale platform would consume more engineering bandwidth than it would save. The unofficial answer is that Cerebras has been capital-constrained relative to NVIDIA and has had to make brutal trade-offs about where to spend. Whether the post-IPO balance sheet — flush with primary capital from the offering — changes this calculus is one of the more interesting open strategic questions facing the company.
A brief second-layer aside that matters: customer concentration in the S-1 is high. G42 alone, in the most recent disclosed reporting period, represented well over half of Cerebras's revenue.1 The audit opinions and risk-factor language flag this explicitly. There is no immediate going-concern issue — the company has primary capital from the IPO and committed forward orders — but the qualitative concentration risk is the single largest non-technical risk overhanging the stock. The bull case, properly stated, requires not just that the cloud business succeeds but that the customer mix diversifies meaningfully within two to three years.
VII. The Playbook: Seven Powers and Porter's Five Forces
When you strip the technical detail away from the Cerebras story and ask what kind of structural advantages the company actually possesses, the answer is more nuanced than the bull-case slide deck would suggest. Hamilton Helmer's Seven Powers framework is a useful lens here, because it forces the analyst to distinguish between genuine durable advantages and the kind of temporary lead that erodes the moment a competitor decides to match it.
Cornered Resource is the strongest power Cerebras possesses, and it is the one that is least appreciated by the casual investor. The cornered resource is not the wafer-scale chip itself — anyone with enough money could, in theory, contract TSMC to attempt a wafer-scale design. The cornered resource is the yield engineering — the proprietary knowledge of how to design redundancy, route around defects, manage the thermal expansion of a 300-millimeter wafer, and bond the whole assembly into a system that actually works in a customer's data center. This is the kind of knowledge that does not live in patents (though Cerebras has many); it lives in the heads of a few hundred engineers and in the manufacturing process steps that have been refined across three generations of WSE products.[^9] An incumbent that wanted to match this would not just need money; it would need to recapitulate nine years of process learning.
Counter-Positioning is the second power, and it is structurally elegant. NVIDIA, the obvious incumbent threat, cannot move to wafer-scale without cannibalizing its own business model. The H100 and Blackwell architectures are sold at very high gross margins specifically because they require expensive NVLink interconnects, expensive InfiniBand networking, and expensive DGX system integration — all of which become unnecessary in a wafer-scale world. If NVIDIA built a wafer-scale chip tomorrow, it would obsolete its own networking and system businesses, which together represent a meaningful share of its data-center revenue. Classic counter-positioning: the incumbent's most profitable business model is exactly the business model the challenger is attacking.
Scale Economies is the weakest of the three powers Cerebras can credibly claim. The argument is that as Cerebras runs more wafers through TSMC, the unit cost falls, allowing the company to underprice competitors. This is true in theory but constrained in practice by the fact that Cerebras's total wafer volume is small compared to NVIDIA's, which means NVIDIA actually enjoys greater absolute scale at TSMC. Where Cerebras may have a scale-economies advantage is in the cloud business: as the installed base of CS-3 systems in Cerebras's own data centers grows, the marginal cost of serving an additional inference request approaches zero, and the company can subsidize price-leadership against AWS Bedrock and NVIDIA DGX Cloud. This is the same dynamic that built AWS itself.
The remaining four powers — Network Economies, Switching Costs, Branding, and Process Power — are largely absent from the Cerebras moat as of 2026. Network effects are weak (this is not a marketplace). Switching costs are real but moderate (a customer that built its model on the CSDK can, with engineering effort, port it back to CUDA). Branding is nascent. Process Power is genuine in the chip design itself but does not extend across the whole business.
Layering Porter's Five Forces on top of the Seven Powers exercise produces a richer picture of the competitive landscape. The threat of new entrants in wafer-scale AI compute is actually low, because of the cornered-resource argument above — the activation energy required to enter this market is enormous. The threat of substitutes is high: any company contemplating a wafer-scale purchase has the obvious alternative of just buying more NVIDIA GPUs, and most will. Buyer power is unusually high in this market, because the buyers are sophisticated and concentrated — a single research lab or sovereign cloud represents an enormous fraction of demand, which is why pricing in this market is heavily negotiated and rarely list-price.
Supplier power, however, is the most underappreciated force in the entire Cerebras analysis, and it deserves to be discussed at length. Cerebras's single largest dependency is on TSMC, which manufactures the WSE wafers at its advanced 5-nanometer and 3-nanometer nodes. TSMC's advanced-node capacity is the single most fought-over industrial resource of the 2020s; Apple, NVIDIA, AMD, MediaTek, Qualcomm, and dozens of smaller customers are all competing for the same slots. Cerebras, by virtue of being a relatively small customer in volume terms, sits behind those giants in the priority queue. In years when TSMC's leading-edge capacity is constrained — which has been most years since 2020 — Cerebras has had to negotiate hard for the wafer allocation it needs. The S-1 discloses TSMC as a critical supplier risk.1 If TSMC ever decided that Cerebras was not worth the slot — or if a geopolitical event in Taiwan forced TSMC to ration capacity — Cerebras's growth would be capped by something entirely outside its control.
Internal industry rivalry is intense but oddly bifurcated. In the GPU-shaped market, NVIDIA is the sun and AMD's MI300 line is a small but credible alternative, with the hyperscaler in-house designs (Google TPU, AWS Trainium, Microsoft Maia) representing meaningful captive demand pulled away from merchant silicon. Cerebras is not competing in that market at all in the architectural sense. It is trying to be, as Feldman has put it, "a different solar system" — a separate architectural category in which the giant chip is the natural unit, and the GPU-shaped infrastructure is the wrong abstraction. Whether the market accepts that framing — whether enterprise customers and sovereign clouds carve out a meaningful share of their compute budget for a non-GPU architecture — is the central commercial question of the next five years.
VIII. Bear vs. Bull Case
Every Acquired-style analysis arrives, eventually, at the moment when the analyst stops describing the company and starts arguing with themselves about whether to believe the story. Cerebras is one of the best companies in the modern semiconductor landscape for this exercise, because the bull case and the bear case both have real teeth.
The bull case begins with the architectural argument and ends with a simple math problem. The architectural argument is that as AI models grow larger — the trajectory from 7 billion parameters in 2022 to 70 billion in 2023 to the 400-billion and 1-trillion parameter models being trained in 2025 and 2026 — the bottleneck shifts from compute (where GPUs excel) to memory bandwidth and interconnect bandwidth (where wafer-scale chips structurally dominate). The math problem is that if Cerebras can capture even a low single-digit share of global AI compute spend by 2030, the implied revenue is in the high tens of billions of dollars annually, against a current run-rate that is a small fraction of that. The bull thesis, properly stated, is not "Cerebras beats NVIDIA." It is "Cerebras becomes the mainframe of AI" — the specialized, expensive, high-performance system that you buy when GPUs are not good enough, in the same way that IBM mainframes still exist in 2026 because there are workloads for which no other architecture is suitable. A "mainframe of AI" outcome would imply a hundred-billion-dollar market capitalization, give or take.
The bull case also relies on the cloud business reaching escape velocity. Cerebras Inference,4 launched in August 2024, has demonstrated genuine technical superiority on inference latency for large open-weights models. If the developer ecosystem coalesces around inference as the dominant deployment workload — which seems likely, given that training is a one-time event for any given model and inference is continuous — then Cerebras's architectural advantage compounds into a recurring-revenue cloud business with potentially attractive gross margins at scale. This is the optionality the bulls are paying for.
The bear case begins with customer concentration and ends with software. Customer concentration is the immediate, balance-sheet-visible risk: G42 represents a majority of revenue, and any disruption to that relationship — a CFIUS-driven unwinding, a strategic pivot by the UAE government, a price renegotiation — would create a near-term revenue cliff. Cerebras's management has been working aggressively to diversify the customer base, and the Cerebras Inference cloud business is the most credible diversification path, but the concentration has not yet meaningfully reduced as of the most recent S-1 amendments.1
The software risk is the deeper, longer-term concern. NVIDIA's CUDA ecosystem is not a moat that was built in a year; it is the product of 18 years of compounding developer investment, library development, university curricula, and open-source community building. Every major framework — PyTorch, TensorFlow, JAX — has decades of optimization work targeting CUDA. Cerebras's CSDK is good, by all accounts, and the company has invested heavily in PyTorch compatibility. But the software lock-in around CUDA is one of the most durable competitive moats in the history of the technology industry, and the bear case is that even if Cerebras's hardware is architecturally superior, the friction of moving an existing workload off CUDA is so high that the market will not bother. A version of this bear case has, in fact, played out repeatedly across the history of chip startups — Graphcore, SambaNova, Habana Labs, Mythic — all of which made credible architectural arguments and all of which failed to crack the software moat.
The geopolitical bear case is the third leg. Cerebras's largest customer is operated by a UAE sovereign vehicle; its core manufacturing happens in Taiwan; its largest competitor is an American company with deep ties to the U.S. government. Any meaningful shift in U.S.-China trade policy, U.S.-UAE relations, or cross-Strait security dynamics could materially reshape the company's business. The CFIUS overhang that delayed the IPO is a preview of how this risk can manifest. The S-1 catalogues a long list of regulatory and geopolitical sensitivities, and any rational long-term investor needs to model the possibility that one or more of these resolves unfavorably.
A useful frame, taking the Seven Powers and Porter analysis together, is to ask: in the steady state of 2030, what is the equilibrium share of AI compute that runs on a non-NVIDIA architecture? If the answer is zero — if CUDA's lock-in is total and irreversible — then Cerebras is a niche supplier to research labs and a sovereign-AI specialty house, and the stock is overvalued. If the answer is twenty percent — if the market bifurcates between mass-market GPU compute and specialty wafer-scale inference for the largest models — then Cerebras is meaningfully undervalued at current trading levels. The honest answer is that nobody knows, and the entire investment thesis on CBRS reduces to a probability-weighted bet on which of those equilibria emerges.
For tracking the trajectory between those outcomes, the KPIs that matter are narrower than the full P&L suggests. There are really only two numbers a long-term investor needs to watch quarter to quarter: the revenue contribution from non-G42 customers as a percentage of total revenue, which tracks the customer-diversification thesis directly; and the gross margin on the Cerebras Inference cloud business, which tracks whether the unit economics of the cloud model are converging toward hyperscaler-like profitability or remaining structurally below GPU-cloud peers. A distant third metric — useful but not load-bearing — is the developer adoption signal in the Cerebras Inference API: the number of independent third-party applications calling the API in a given month, which tracks the software-moat-erosion thesis.
That is the bear-bull frame. The valuation argument is layered on top of it, and the valuation argument is a function of how the market chooses to weight those probabilities.
IX. Epilogue and Closing
The Cerebras IPO prospectus, when it was first filed with the SEC on September 30, 2024,1 was a document that asked the market to take a series of leaps of faith. Take the leap that wafer-scale architecture is the future of AI compute. Take the leap that a single Emirati customer representing the majority of revenue is a strategic asset rather than a balance-sheet liability. Take the leap that an emerging cloud business launched only months before the filing will become a multi-billion-dollar revenue engine. Take the leap that the CFIUS process will eventually resolve. Take the leap that TSMC will continue to allocate advanced-node capacity to a company that, by wafer volume, is one of its smaller customers. Take the leap that the software moat around CUDA will, somehow, prove permeable.
By May 2026, with CBRS now trading on NASDAQ following the resolution of the CFIUS review and the subsequent pricing of the offering, the market has begun, tentatively, to take some of those leaps. Whether it has taken too many or too few is the central question of the post-IPO period. The S-1 financials show a company growing revenue rapidly but burning cash at a rate consistent with continued investment in data-center build-outs for the cloud business.1 The burn-versus-growth ratio is the kind of number that, for an early-stage cloud business, is often a feature; for a hardware company, is often a bug; and for Cerebras — which is both — is genuinely difficult to evaluate against any obvious comparable.
There is no obvious comparable. NVIDIA is a useful reference point for revenue scaling and gross margin trajectory, but NVIDIA's business model is structurally different. Intel is a useful reference for the perils of leading-edge manufacturing dependence, but Intel manufactures in-house. AMD is a useful reference for the politics of competing against NVIDIA, but AMD's GPU business is architecturally orthodox. Snowflake and Databricks are useful references for the economics of building a fast-growing infrastructure cloud, but neither of them designs their own silicon. The closest historical analog might be Cray Research in the 1980s — a specialty supercomputer maker that built defensible architectural advantages, sold to elite buyers, and ultimately reached a steady state as a niche supplier to the workloads that no commodity vendor could serve. Whether that is Cerebras's destiny — and whether that destiny is large enough to justify the multiple the market is paying — depends on how the next two product generations land.
The next product generation, the WSE-4, is rumored to be in tape-out as of 2026. Cerebras has not committed to a public launch date, but the cadence of WSE-1 (2019), WSE-2 (2021), and WSE-3 (2024) suggests a 2026 or 2027 announcement window.[^1] The architectural rumor is that WSE-4 will move to TSMC's 3-nanometer node and will significantly increase the on-die SRAM, which would further widen the memory-bandwidth advantage over GPUs for inference workloads. If the WSE-4 lands on schedule with the expected specifications, the bull case strengthens materially. If it slips, or if the architectural improvements disappoint, the bear case gets a meaningful new data point.
Andrew Feldman, in interviews around the IPO, has been characteristically uncompromising about the long-term vision. He has stated, in various forms, that he believes the AI compute market will eventually bifurcate into commodity GPU compute for general-purpose workloads and specialty wafer-scale compute for the largest, most latency-sensitive models — and that Cerebras intends to dominate the latter category. He has been equally clear that he does not believe the company should try to compete with NVIDIA in the general-purpose category; that would be, in his framing, doing what is easy rather than what is hard. Whether that vision is right is, ultimately, a question that will be answered not by the analysts but by the workloads themselves — by which AI applications, in 2028 and 2030, run on which silicon.
There is something poetic about the fact that the company attempting the most audacious hardware bet in modern Silicon Valley history was founded by a team whose previous company tried, and failed, to do almost exactly the opposite — to build a server out of as many small chips as possible rather than out of a single giant one. The lesson the SeaMicro founders took from that earlier experience — that the bottleneck is the wire, not the processor — is the lesson that has animated every architectural decision at Cerebras since 2015. Whether that lesson turns out to be the correct lesson for the AI era, or whether NVIDIA's bet that a clever enough networking fabric can hide any latency turns out to be the correct lesson, is the kind of question that the market will spend the next decade answering.
For now, the dinner plate sits in the data center, doing inference at twenty times the speed of the cracker-sized alternative, with a single Emirati customer accounting for the majority of forward bookings and a founder whose conviction has, so far, outlasted every prediction of his failure. The wafer-scale revolution, whatever it turns out to be worth, has at least made it to the public markets. From here, the story belongs to the workloads.
 RSS Feed
RSS Feed Spotify
Spotify Apple Podcasts
Apple Podcasts Amazon Music
Amazon Music Audible
Audible YouTube
YouTube